项目介绍
又在GitHub上发现一个好玩的开源项目–AI-Video-Transcriber(AI视频转录器),它支持YouTube、Tiktok、Bilibili等30+平台,以及本地视频文件的智能转录、多语言摘要功能,通过本教程,你将从零开始,逐步掌握如何将这个项目部署到生产环境。
环境准备:确保系统兼容性
在开始部署前,请确保您的系统满足以下要求:
- Python 3.8+:项目基于Python开发,建议使用最新稳定版本。
- FFmpeg:用于视频和音频处理,是转录功能的依赖项。
- 可选LLM服务:如果您需要使用AI优化功能(如摘要生成),需配置OpenAI API密钥或本地Ollama服务。
安装FFmpeg(以常见系统为例):
- macOS:使用Homebrew安装:
brew install ffmpeg - Ubuntu/Debian:运行:
sudo apt update && sudo apt install ffmpeg - Windows:从FFmpeg官网下载二进制文件并添加到系统PATH。
如果您的系统尚未安装Python,建议从Python官网下载安装包,或使用包管理器(如macOS的Homebrew)进行安装。
部署方法一:自动安装(推荐新手)
自动安装脚本简化了部署流程,适合快速上手。
- 克隆项目:打开终端,运行以下命令下载项目代码:
git clone https://github.com/tiandaoyuxi/AI-Video-Transcriber.git
cd AI-Video-Transcriber - 运行安装脚本:执行安装脚本,自动处理依赖和环境设置:
chmod +x install.sh
./install.sh提示:如果脚本执行失败,检查系统权限或手动安装依赖(见方法三)。
部署方法二:Docker部署(最适合生产环境)
Docker提供了隔离且一致的运行环境,适合长期使用。
- 克隆项目并配置环境:
git clone https://github.com/tiandaoyuxi/AI-Video-Transcriber.git
cd AI-Video-Transcriber
cp .env.example .env - 编辑环境变量:打开.env文件,设置您的API密钥或Ollama配置。例如:
# 对于OpenAI
OPENAI_API_KEY=your_api_key_here
# 对于Ollama
OLLAMA_BASE_URL=http://localhost:11434/v1
OLLAMA_MODEL_NAME=llama3 - 启动服务:使用Docker Compose一键部署:
docker-compose up -d
小贴士:如果端口8000被占用,可修改docker-compose.yml文件中的端口映射,例如改为8001:8000。
- 验证部署:访问http://localhost:8000,如果看到Web界面,说明部署成功。
部署方法三:手动安装(适合自定义需求)
手动安装让您更灵活地控制环境,适合高级用户。
- 创建 Python 虚拟环境:避免依赖冲突。
python3 -m venv venv
source venv/bin/activate # Windows 系统使用:venv\Scripts\activate - 安装 Python 依赖:
pip install -r requirements.txt
- 配置环境变量:设置 API 密钥或 Ollama 服务,例如在终端中临时设置:
export OPENAI_API_KEY="your_openai_api_key_here"
#或对于Ollama
export OLLAMA_BASE_URL="http://xxx.xxx.xxx.xxx:xxxxx/v1" - 启动服务:运行启动脚本,建议生产模式以保持连接稳定:
python3 start.py --prod
注意:生产模式禁用热重载,适合处理长视频。
使用指南:从部署到实战
部署完成后,测试项目功能:
- 访问Web界面:在浏览器中打开http://localhost:8000。
- 输入视频源:粘贴YouTube或Bilibili视频URL,或上传本地视频文件。
- 选择语言:设置摘要语言(如中文或英语)。
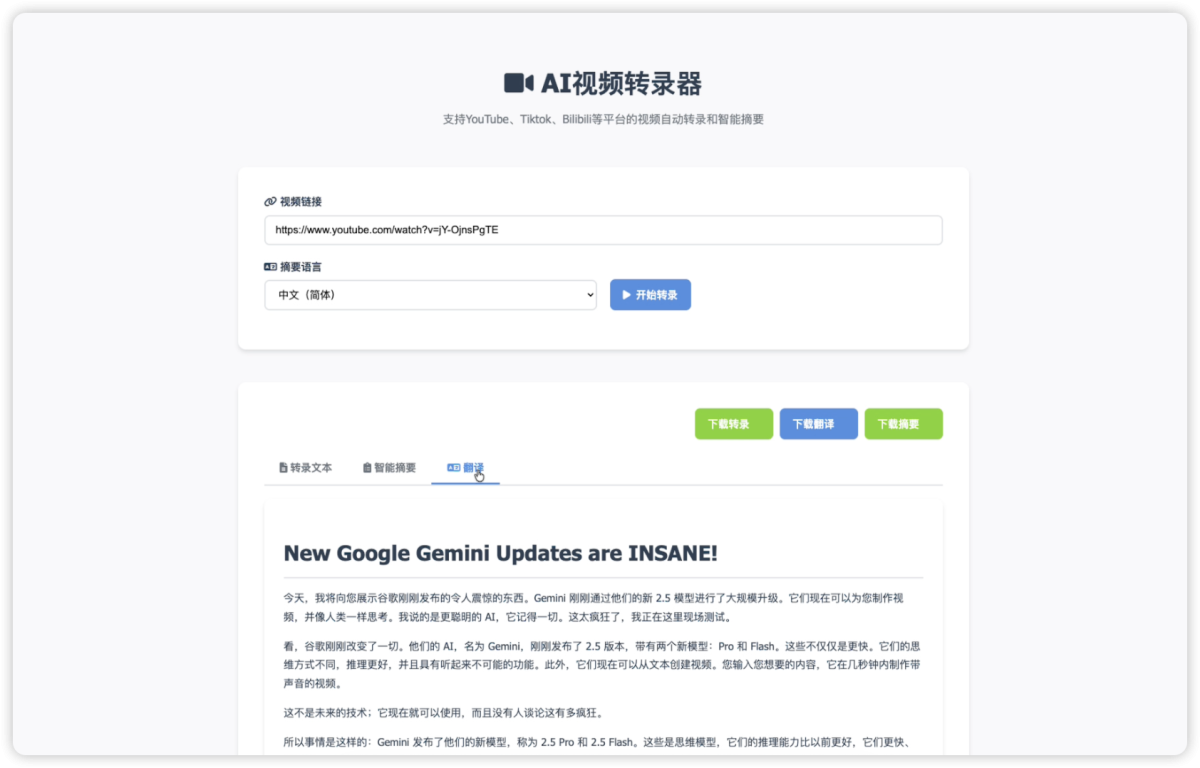
- 开始处理:点击“开始”按钮,系统将自动下载视频、转录音频、生成摘要。实时进度条会显示每个阶段的状态。
- 查看结果:处理完成后,您可以在界面中查看优化后的转录文本和智能摘要。如果转录语言与摘要语言不同,还会提供翻译选项。
常见问题与优化建议
- 问题1:转录速度慢
解决方案:尝试使用较小的Whisper模型(如tiny或base),通过设置环境变量WHISPER_MODEL_SIZE=tiny。 - 问题2:Docker容器启动失败
排查步骤:检查.env文件配置,运行docker logs 查看日志,确保网络连接正常。 - 性能优化:对于长视频,项目自动分段处理。如果内存不足,可限制Docker容器内存:docker run -m 1g -p 8000:8000 –env-file .env ai-video-transcriber。
© 版权声明
文章版权归智潮派所有,未经允许请勿转载。
相关文章
暂无评论...
智潮派是一个专注于AI工具导航与实用教程的内容站点,帮助用户高效发现和使用各类AI工具。
